
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- joint training of textual and layout information
- Test set
- Text Recognition
- VrDU
- OCR
- Pre-training
- layoutlm
- layoutxml
- document image understanding
- 레이블링
- 딥러닝
- document understanding
- multilingual
- Today
- Total
JM_Research Blog
LayoutLMv2: Multi-modal Pre-training for Visually-rich Document Understanding 본문
LayoutLMv2: Multi-modal Pre-training for Visually-rich Document Understanding
-jm- 2024. 3. 26. 18:07🌞Summary
이번 포스팅은 text 정보와 layout 정보를 같이 통합하여 모델링 한 LayoutLM의 후속작인 LayoutLM2입니다.
해당 논문을 통해서 document image understanding task에서는 text 정보와 layout 정보를 어떻게 잘 통합하여서 학습시킬 것인지에 중점을 두고 발전하는 것 같습니다.
LayoutLMv2에서 주의깊게 봐야할 점은 전 모델과의 차이점입니다. 이를 통해 LayoutLMv2를 더 깊게 이해할 수 있으리라 생각됩니다.
ABSTRACT
task : document image understanding
본 논문은 textual and layout information 정보 간의 상호작용을 통합하여 모델링하는 LayoutLM의 후속작인 LayoutLMv2를 제안합니다.

LayoutLMv2를 더 잘 이해하려면, 이전 버전인 LayoutLMv1과 비교해 보는 것이 도움이 될 것입니다.
LayoutLMv1 vs LayoutLMv2
1. visual information을 pre-training 단계에 반영 ↔ v1은 fine-tuning 단계에만 적용
2. pre-training strategies 에서 새롭게 추가된 two new training objectives
- 기존 masked visual-language modeling
- + new text-image alignment
- + text-image matching
3. spatial-aware self-attention mechanism
- 2-D relative position representation for token pairs 와 결합됨
LayoutLMv2
1. visual information을 pre-training 단계에 반영 ↔ v1은 fine-tuning 단계에만 적용
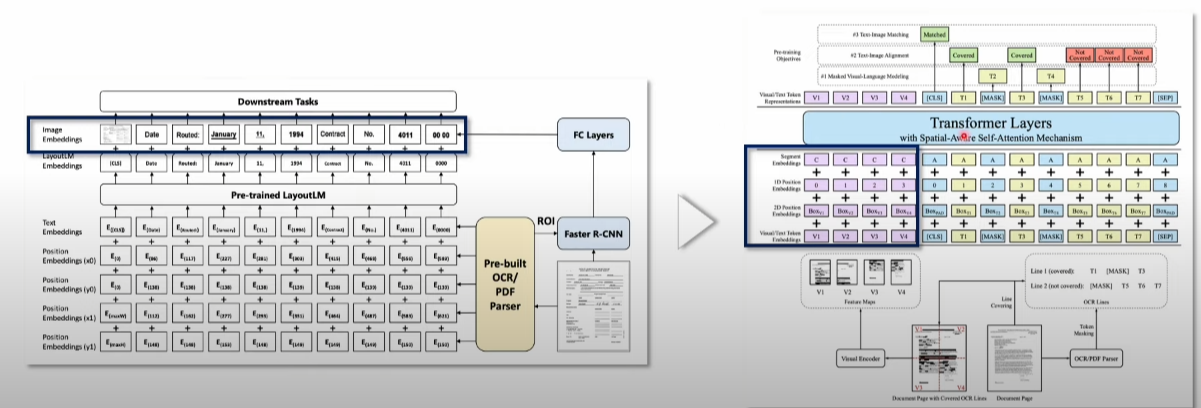
LayoutLMv2에서는 visual information을 fine tuning 단계 뿐 아니라 pre training 단계에도 적용을 하였습니다. 먼저 LayoutLMv2에서의 input을 살펴보도록 하겠습니다. LayoutLMv2에서의 input은 Text Embedding 과 Visual Embedding, Layout Embedding 으로 구성됩니다.
Text Embedding

Text Embedding 은 Text token Embedding + Layout Embedding 으로 구성되어 있습니다.
Text token Embedding t_i = TokEmb(w_i)+PosEmb1D(i)+SegEmb(s_i)
Layout Embedding l_i = Concat(PosEmb2D_x(x_min, x_max, width), PosEmb2D_y(y_min, y_max, height)
- Text token bounding box_i = (x_min, x_max, width, y_min, y_max, height)
- [CLS], [SEP], [PAD] 와 같은 token들의 bounding box은 (0,0,0,0,0,0)으로 처리됩니다.
Visual Embedding
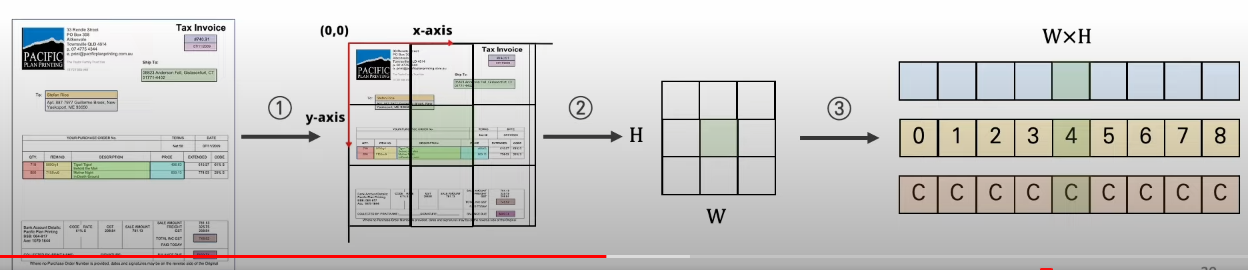

Visual Embedding 은 Visual token Embedding + Layout Embedding으로 구성되어 있습니다.
Visual token Embedding v_i = Proj(VisTokEmb(I)_i) + PosEmb1D(i) + SegEmb([C])
- Proj(VisTokEmb(I)_i) 를 구하는 과정은 다음과 같습니다.
- 1) 전체 이미지 -> 224x224 resize
- 2) resize된 이미지를 visual backbone 모델의 입력으로 넣게 되고 이를 통해 7x7 feture map을 얻게 됩니다.
- 3) linear projection layer 를 통해 WxH의 사이즈로 projection 합니다.
Layout Embedding l_i = Concat(PosEmb2D_x(x_min, x_max, width), PosEmb2D_y(y_min, y_max, height)
2. pre-training strategies 에서 새롭게 추가된 two new training objectives
LayoutLMv2에서는 기존의 masked visual-language modeling 뿐만 아니라 text-image alignment와 text-image matching이라는 두 개의 새로운 training objectives를 추가하였습니다.
Text-Image Alignment
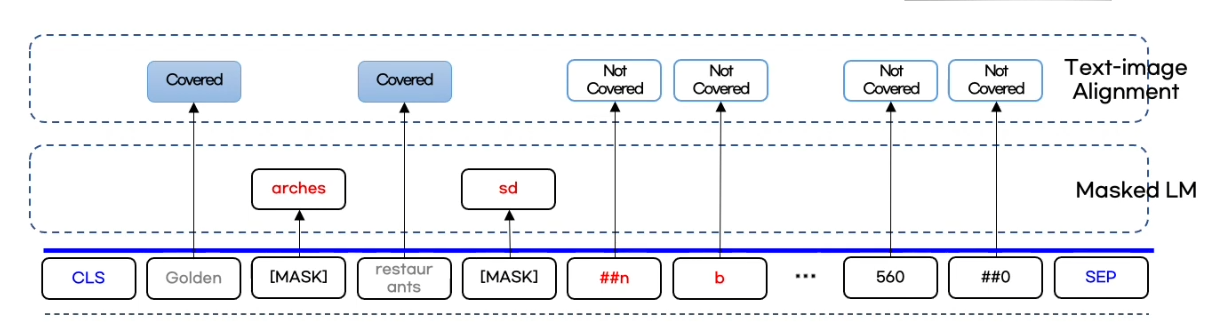
이미지에서 특정 토큰을 랜덤하게 마스킹한 후 텍스트에서 해당 토큰이 이미지에서 가려져 있는지 아닌지 예측하는 task로 MLM에 사용된 token은 고려하지 않습니다.
Text-Image Matching

Text-Image Matching은 입력으로 함께 주어진 이미지와 텍스트가 같은 문서로 나온것인지 아닌지 이진 분류하는 task입니다. 문서 이미지와 text 간의 대응관계를 학습하기 위한 task이며, 해당 task는 맨 처음 CLS token의 output을 이용하여 이진분류를 수행합니다. 여기서 positive sample은 기존 구성된 입력 인풋들을 의미하고 negative sample들은 이미지를 랜덤하게 교체(15%) 하거나 이미지를 drop(5%)하는 방식으로 구성하였습니다.
참고문헌
더 자세한 내용을 보고 싶으시다면 해당 자료를 살펴보시기 바랍니다.
1. paper : https://arxiv.org/abs/2012.14740
LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding
Pre-training of text and layout has proved effective in a variety of visually-rich document understanding tasks due to its effective model architecture and the advantage of large-scale unlabeled scanned/digital-born documents. We propose LayoutLMv2 archite
arxiv.org
2. 참고 자료 : https://www.youtube.com/watch?v=3yOQXVUJ6h8&t=1823s
3. 참고 자료 : https://www.youtube.com/watch?v=BI2Mx5cdc60&t=273s
(정말 많은 도움 되었습니다 감사합니다 😊😊)



