
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 딥러닝
- Test set
- 레이블링
- multilingual
- document image understanding
- joint training of textual and layout information
- VrDU
- layoutxml
- Text Recognition
- layoutlm
- OCR
- Pre-training
- document understanding
- Today
- Total
JM_Research Blog
[nlp study] transformer 본문
본 포스팅은 고려대학교 산업경영공학부 DSBA 연구실의 Unstructured Data Analysis (Text Analytics) 강의를 리뷰한 것입니다. 많은 도움이 되었습니다. 감사합니다 😀 (문제 발생 시 해당 포스팅은 삭제하도록 하겠습니다)

transformer 개요
•순환 신경망(RNN)이나 컨볼루션 신경망(CNN)에 비해 더 빠르고 효율적으로 대량의 텍스트 데이터를 처리할 수 있음 → 한꺼번에 attention이 가능하도록 하는 모델
•구조 : encoder, decoder
•다수의 encoding, decoding layer로 구성됨
•encoder : unmasked 방식 사용
•decoder : maskd 방식 사용
•문장을 생성해야 하기 때문에 뒷 단어를 먼저 생성할 수 X → masked 방식으로 순차적으로 생성
Encoder

•특징
•encoder layer는 모두 같은 구조
•가중치 공유는 X
•구성 : 2개의 sub layer로 구성
•Self-Attention layer
•인코더가 특정 단어를 인코딩할 때 해당 sequence의 다른 token들을 얼마만큼 중요하게 볼 것인지 정하는 layer
•Feed-Forward Neural Networks
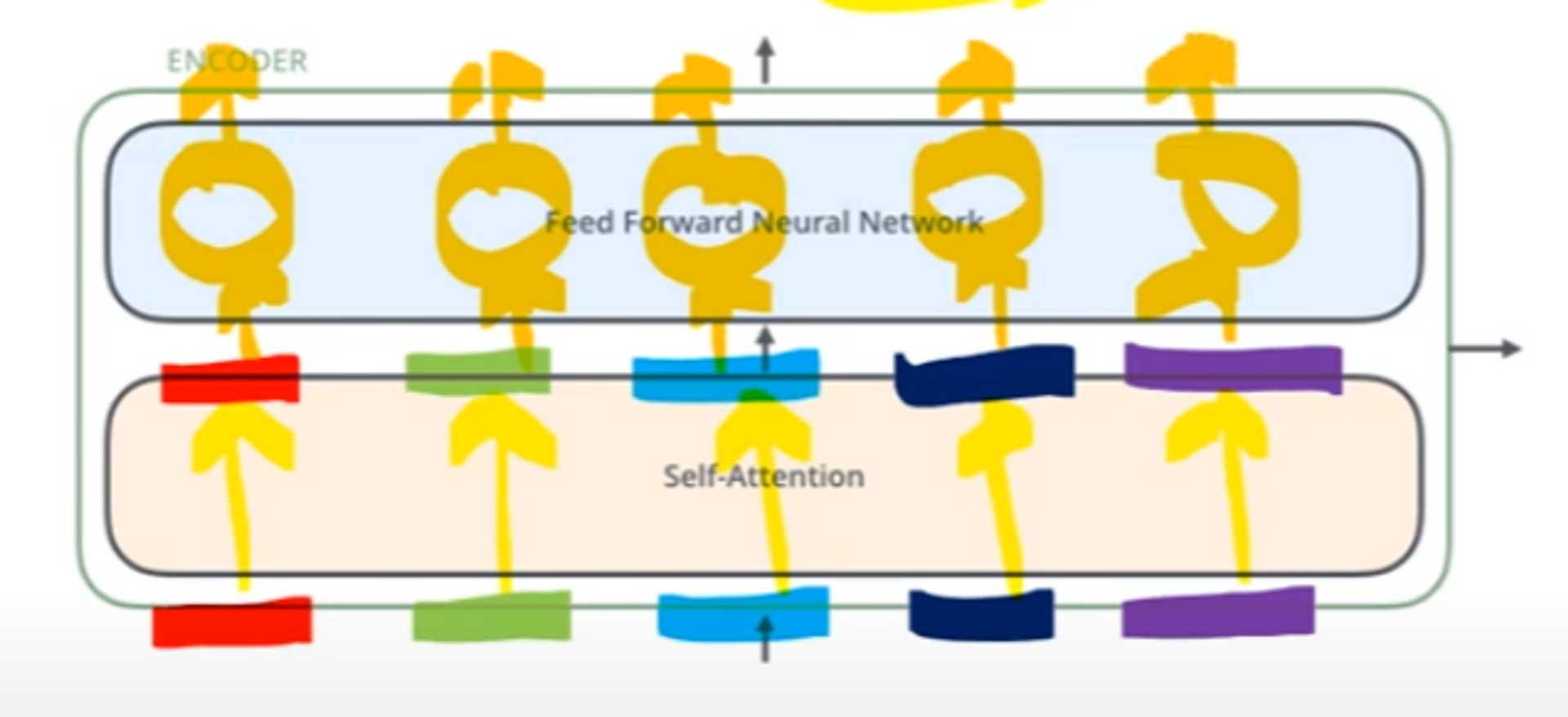
•동일한 Feed-Forward Neural Networks가 각 포지션에 독립적으로 적용
•각 word의 수에 맞게 독립적으로 적용됨
Decoder

•특징
•encoder-decoder attention layer
•decoder는 encoder에서 받은 정보들을 반영하는 layer 가 추가로 존재
transformer 세부
Encoder
1. input embedding

•input 단어에 대한 embedding 작업
•word embedding, glove, fast text 사용
•제일 첫 번째 encoder block의 입력으로 사용됨(bottom-most encoder)
•차원은 512 차원
•size는 layer를 거치더라도 계속 유지
•size는 하이퍼파라미터
•한 sequence의 최대 길이를 뜻함
2. positional encoding

•rnn 같은 경우는 sequence가 보존이 되는데 transformer는 한꺼번에 모든 sequence를 입력으로 받기 때문에 sequence 정보가 보존되지 않음
•각 단어의 sequence 정보(위치 정보)를 보존해 주고자 만듦
•특징
•각 input embedding에 더해지는 vector
•수식
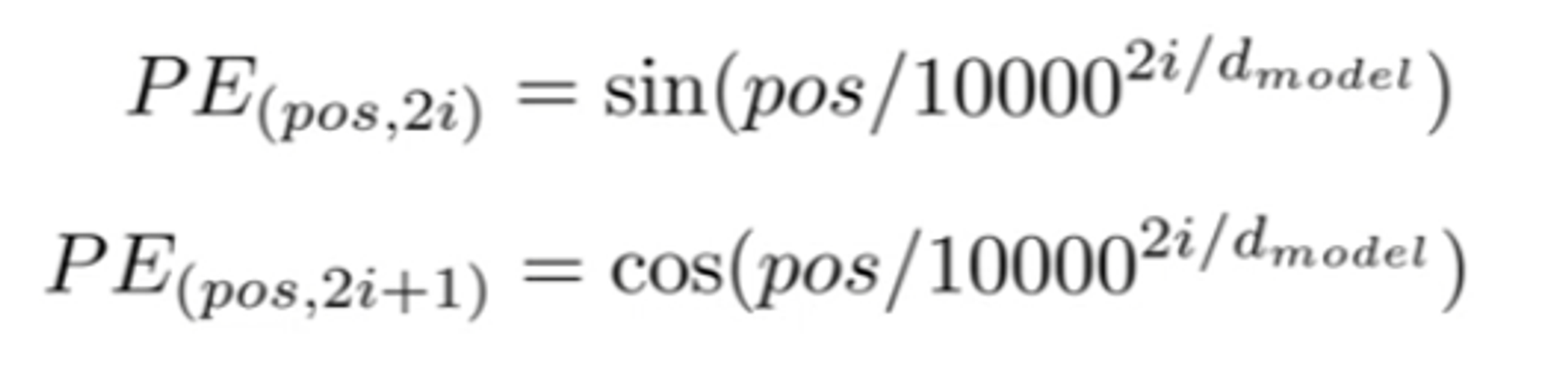
•벡터의 사이즈는 동일하고, sequece가 멀어질 수 록 PE 또한 커지도록
3. self-attention layer
•self-attention 특징

•it 과 연관이 있는 단어들은 무엇인지 답을 주는 역할
•현재 처리하는 input sequence와 연관된 다른 단어에 대한 의미 파악
•it 과 어떤 단어가 관계가 높은지 확인 가능(색이 진한 것이 관계 높음)

•동작 순서
•Step 1 : 각 input vector 들에 대해서 3 종류의 vector를 만듦

•query : 현재 단어에 대한 표현
•key
•각 단어들의 label과 같은 역할 수행
•어떤 query 가 주어졌을 때 key를 통해 관련이 깊은지 파악 가능
•value : 실제 값, 각 단어에 대한 정보를 담고 있음
→ query와 key 를 통해서 가장 적절한 value 를 찾아 연산하겠다!
•query key value 생성과정
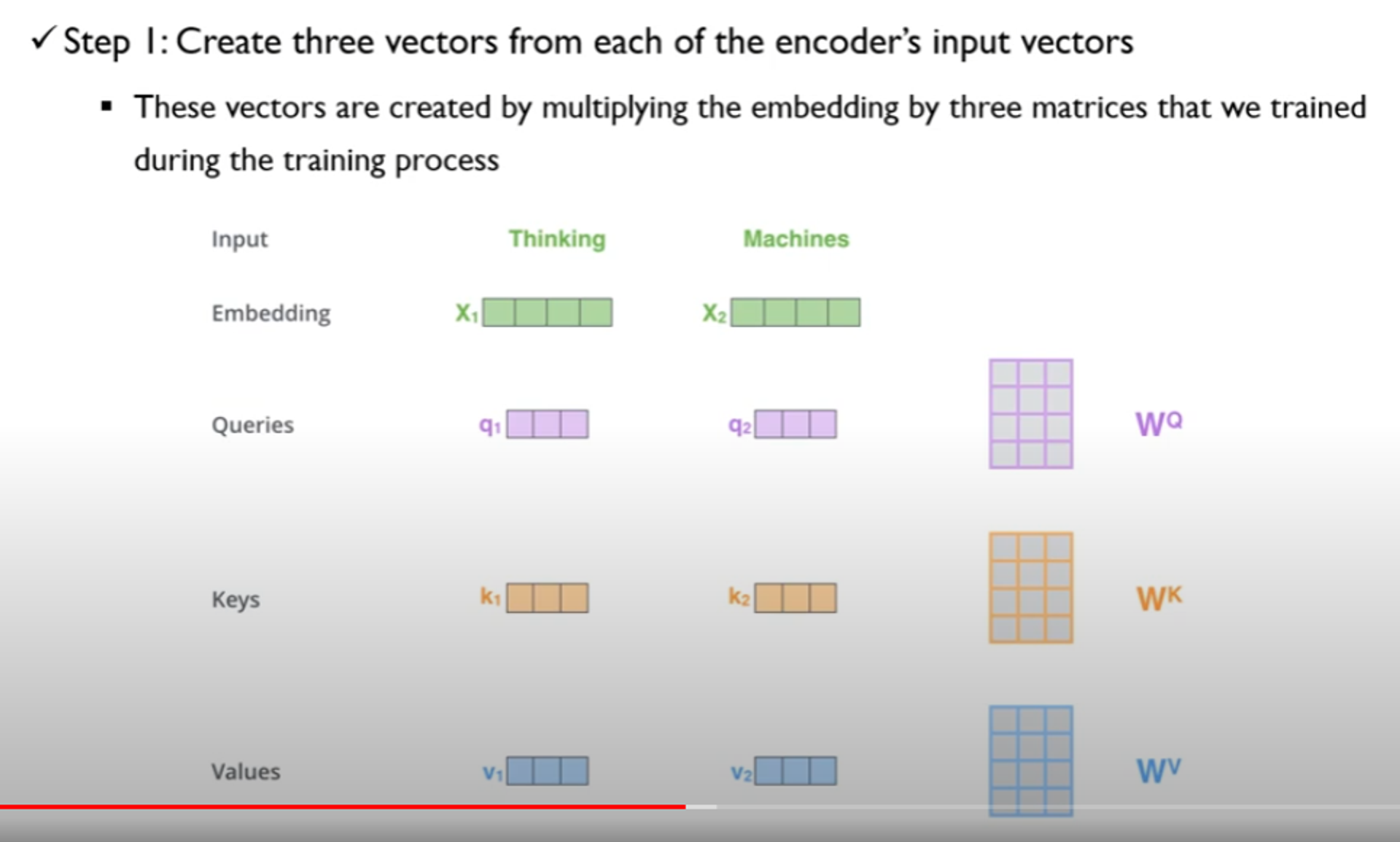
•input embedding과 연산으로 부터 구해짐
•WQ, WK, WV 는 학습을 통해서 찾아야하는 미지수
•q1 = X1 x WQ 으로 구해짐
•X1(1,4) , Wq(4,3) = 1,3 행렬
• query key value 벡터들은 input embedding vector의 사이즈 보다 작음
•input embedding = 512
•query key value = 64
•512 = 64 x 8 → 8은 multi head의 수
•Step 2 : query 와 가장 관련성이 높은 key 는 무엇인지 계산

•score는 현재 query 들을 모든 key 들과 곱해서 구함
•Step 3,4

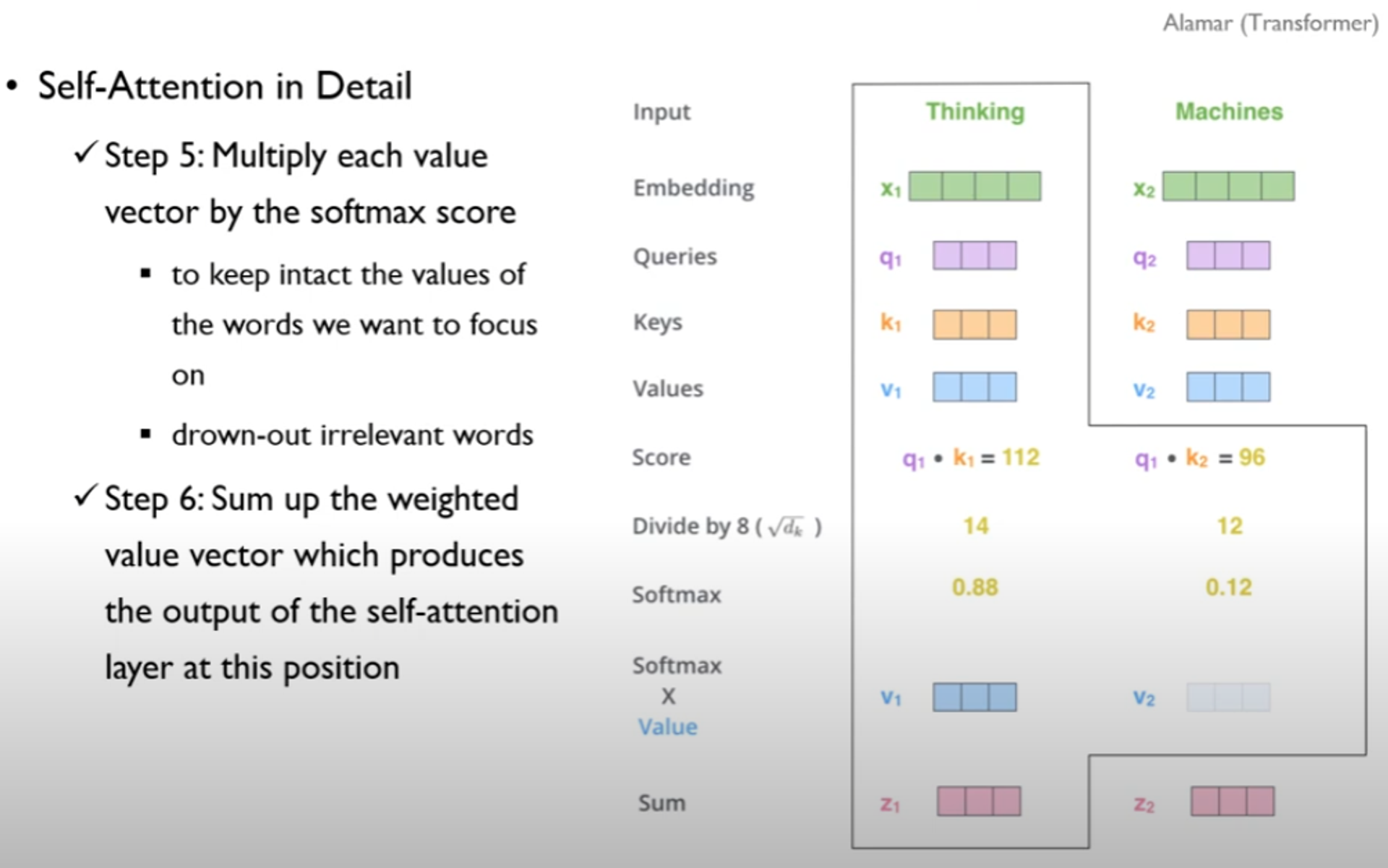
•step 3 : 구한 score를 루트(차원의 수)로 나눠줌
•step 4 : softmax operation 수행
•의미 : 현재 보고 있는 token에 대한 각 단어들의 중요도
•step 5 : softmax 값 x value
•Step 6

• softmax들에 의해서 가중치가 반영된 value들을 모두 합함
•z1 = v1 + v2 + ....
•Step 1~6 과정을 matrix 연산

4. multi-head attention
여러 개의 Attention 메커니즘을 병렬로 사용하여 다양한 관점에서 입력 데이터를 해석
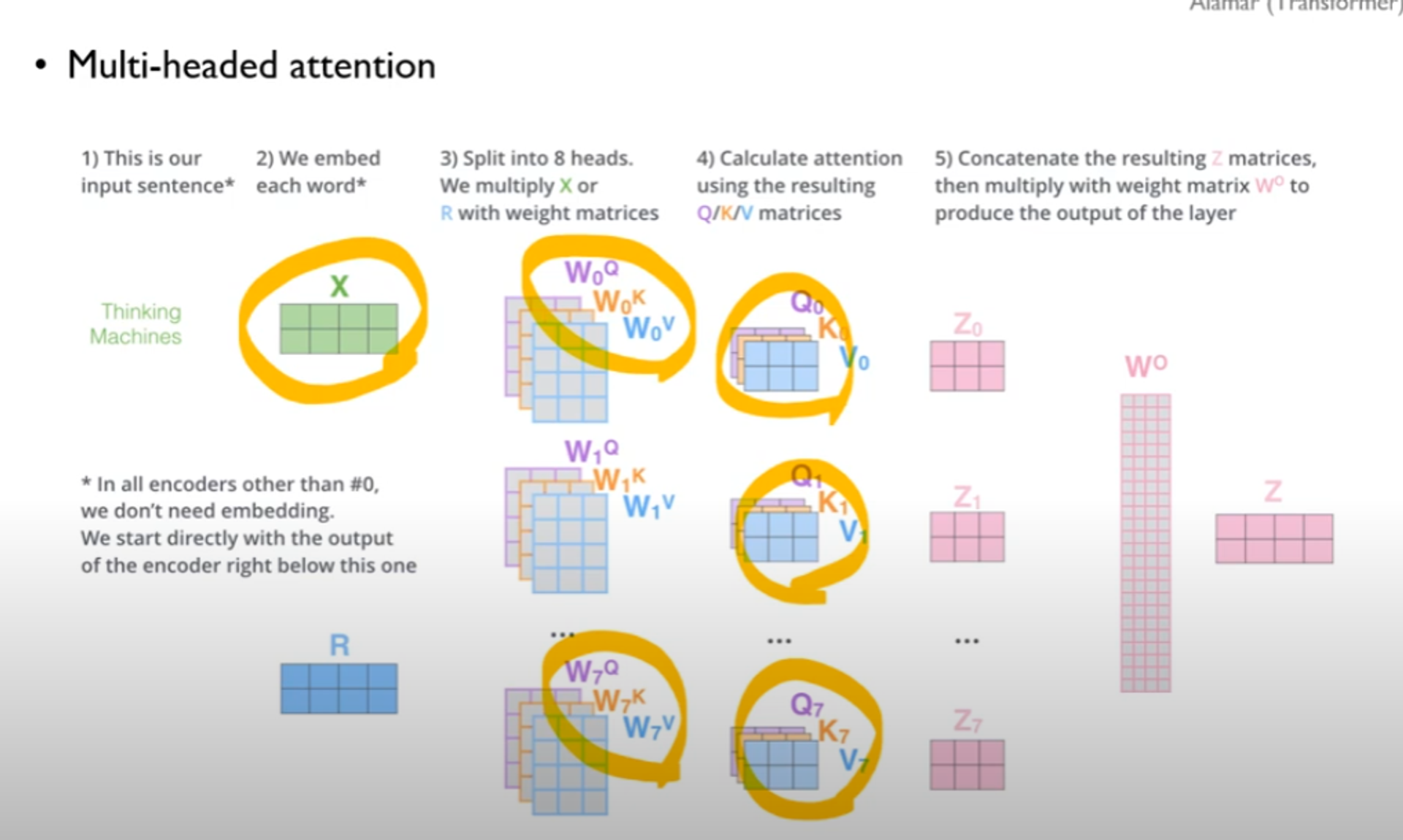
•self attention layer 의 output은 input size와 동일함
•R = 이전 encoder의 output
•이 역시 input size와 동일함 → 차원의 크기 보존
5. residual & normalize
residual : self-attention 을 통해 도출된 z와 입력 x1을 더함

6. feed-forward neural networks

•encoder block의 마지막 부분
•fully connected feed-forward network
•각 포지션들에 대해서 독립적으로 수행됨
•but, ffn은 하나의 layer → convolution 연산을 통해 독립적으로 수행되는 것처럼 연산
•FFN(x) = max(0, xW1+b1)W2+b2
•앞은 relu function
decoder
1. masked multi-head attention
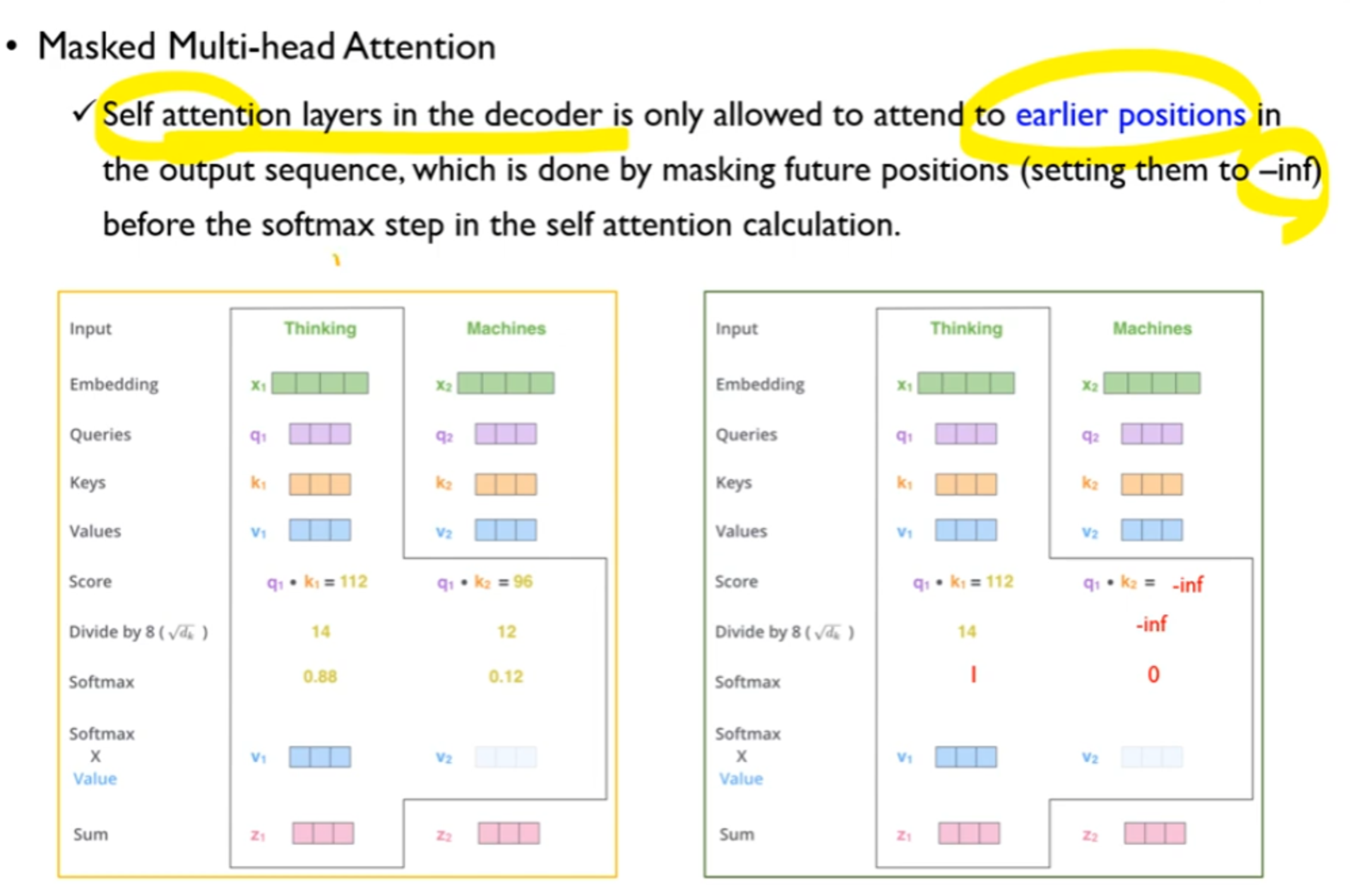
•decoder의 self-attention layer는 output sequence 앞의 포지션만 참조 할 수 있음
•future poosition의 score 값을 -inf 로 masking함 → sofmax 0
•실제 계산 예시

2. decoder side

•encoder의 output 과 decoder와의 연결부분
•encoder output key value 와 decoder output query 에 대해서 self-attention 함
3. final Linear and softmax layer


최종 output : Liner layer (fcn) → sofmax
참고자료
더 자세한 내용을 보고 싶으시다면 해당 자료를 살펴보시기 바랍니다.
1.08-2: Transformer 강의영상 : https://www.youtube.com/watch?v=Yk1tV_cXMMU&list=PLetSlH8YjIfVzHuSXtG4jAC2zbEAErXWm&index=17



